O que é pipeline
April 4, 2026 portugues pipeline as code pipeline devops qa
Contextualização
Para entender pipeline é preciso antes falar que esse contexto é de uma entrega mais automatizada possível, ou seja, que alguma parte do processo de entrega de software, uma parte dela será executada automaticamente.
Antes da existência das ferramentas de pipeline de software, era comum as pessoas fazerem cada etapa do processo manualmente, o que demandava muito mais tempo.
A utilização de pipeline hoje é praticamente padrão, raramente você encontrará uma empresa, que tenha algum nível de maturidade com desenvolvimento de software, que não tenha alguns pipelines rodando em sua empresa.
Nesse artigo falaremos sobre o que é pipeline, porque usar essa ferramenta e como normalmente se utiliza algo tão importante para a entrega automatizada de produtos.
É importante que a pessoa já saiba usar basicamente o repositório git para entender completamente esse artigo, mas vale a leitura mesmo sem ele.
Esse artigo é uma versão atualizada do artigo “O que é pipeline”, onde o conteúdo foi revisado e atualizado para refletir uma nova forma de explicar os conceitos, usando exemplos práticos com Github Actions.
Introdução
O pipeline usado para entregar software segue o mesmo conceito usado normalmente nas indústrias.
Dentro de uma fábrica moderna, temos uma esteira metálica, onde são depositados os produtos e essa esteira faz esses produtos se movimentarem, e os robôs, que estão parados, montam o produto à medida que ele passa.
Usando o exemplo da fabricação de carros, primeiro a estrutura metálica do carro (chassi) é colocada no pipeline e ela é movimentada pela fábrica, o primeiro robô, que está parafusado no chão, é responsável por pintar o chassi completamente. Sendo assim, a cada chassi colocado no pipeline o primeiro robô pintará ele automaticamente. É uma tarefa repetitiva e previsível. Você sabe que colocando um chassi no começo, o primeiro robô fará o que se espera dele.
Quando o chassi chega no primeiro robô, o pipeline para, pois o robô precisa de um tempo no processo de pintura, e somente após terminar o pipeline se movimenta novamente, para que o chassi seguinte seja movido para passar pela etapa de pintura e assim sucessivamente.
O segundo robô nesse pipeline é responsável por colocar as rodas e nesse processo o pipeline também espera ele terminar, e somente quando ele acaba o pipeline se move novamente.
No pipeline de software é bem parecido, sendo que ao invés do chassi, nesse modelo temos o código como “objeto” a ser movido pela esteira do pipeline de software.
Como criar um pipeline de software?
Todo código produzido em uma organização deve ser enviado para um repositório central, que será responsável por manter todo mundo que usa aquele código atualizado sobre possíveis mudanças.
Esse repositório normalmente é o git, usado em produtos online como Github e Gitlab.
Nesse artigo usaremos o Github como repositório de código e Github Actions como pipeline, mas tudo o que será dito aqui se aplica igualmente a qualquer outro produto.
Normalmente uma ferramenta de pipeline é configurada para atuar automaticamente com base em mudanças no código hospedado no repositório de código. Vamos para um exemplo mais prático:
Imaginando um repositório chamado gomex/projeto_super_legal e tenho meus códigos já depositados lá. Esse código atual tem uma versão em funcionamento de um projeto super legal e alguém deseja mandar um pedido de modificação desse código abrindo um Pull Request (se você não sabe o que é Pull Request, veja esse artigo) e ao criar o pull request o Github gera um evento que pode ser configurado para iniciar automaticamente um pipeline criado no Github Actions.
Para facilitar o entendimento, vamos criar nosso primeiro pipeline no Github Actions.
Crie um repositório no github e clone ele pra sua máquina, dentro da pasta do seu repositório clonado localmente, crie as seguintes pastas:
.github/workflows
A pasta .github precisa estar na raiz do seu repositório, que é o lugar fora de qualquer pasta do seu repositório. E dentro da pasta .github deve ter uma pasta chamada workflows. E dentro dessa pasta você vai criar um arquivo chamado primeiro_pipeline.yaml. Dentro desse arquivo você colocará o conteúdo abaixo:
name: Meu primeiro pipeline
on: [pull_request]
jobs:
ci:
runs-on: ubuntu-latest
steps:
- run: echo "🎉 Parabéns você criou seu primeiro pipeline"
Antes de rodar seu pipeline, deixa eu lhe explicar esse arquivo.
No arquivo acima ele começa com:
name: Meu primeiro pipeline
Isso é o nome do seu pipeline. Coloque um nome bem claro para que se destina a esse pipeline.
on: [pull_request]
Essa é a linha que chamamos de trigger (gatilho), que é a condição para que esse pipeline seja iniciado. Normalmente os gatilhos estão associados a eventos que acontecem dentro da ferramenta usada para hospedar o código, que no nosso exemplo é o Github.
Ao fazer commit e push desse código para o repositório central no Github, seu pipeline estará pronto para funcionar.
Crie uma branch nova no seu repositório local:
git checkout -b testando_pipeline
E nessa branch nova você fará uma mudança qualquer, pode ser a modificação de um arquivo existente ou a criação de um arquivo novo:
echo “Testando o pipeline” > README.md
Faça o commit e push dessa branch e crie um pull request no seu no Github. Veja que no Pull Request aparecerá o seu pipeline sendo executado, ou seja, sempre que qualquer pessoa criar um Pull Request nesse repositório, ele automaticamente rodará esse pipeline.
Veja nesse link todas as opções de gatilhos (triggers) para iniciar um pipeline no Github Actions
A parte do código relacionado a jobs e steps explicaremos a seguir.
Etapas do pipeline de software
O código é colocado na “esteira” e ela caminha de forma parecida com o que foi usado no exemplo da montagem do carro, ou seja, o código chega no primeiro “robô” e ele executa uma função específica e repetitiva. Esse momento é normalmente chamado de “step”. A tradução para português seria “etapa”, mas usaremos o termo em inglês, pois além de introduzir e fixar um termo tão importante nesse idioma, é esse nome que é usado em boa parte das ferramentas de mercado.
É correto dizer que a execução completa de um pipeline é a “movimentação” do código por múltiplos steps, ou seja, o código é depositado na esteira e transferido para o primeiro step que fará a primeira intervenção no código, que pode ser uma validação estática do código. Esse mesmo código, que foi validado na primeira step passa para uma nova, que pode ser a responsável por transformar esse código em um executável, e na posterior esse artefato é armazenado em repositório.
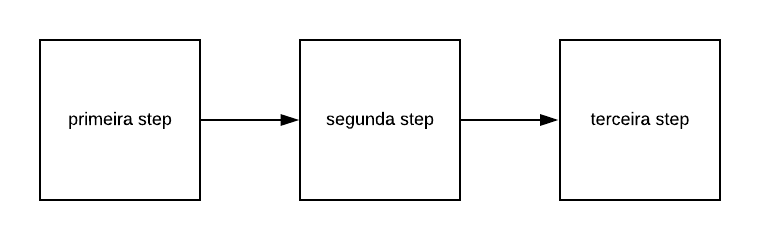
Perceba que no exemplo demonstrado na imagem o mesmo código passou por três steps diferentes na mesma execução do pipeline.
Cada step do seu pipeline é um comando, que é executado em uma console. Essa execução normalmente é executada dentro da pasta que tem os arquivos atualizados que foram recém baixados do controle de versão.
Na imagem anterior, a primeira step seria um comando para avaliar estaticamente o código fonte que está na sua pasta local, a segunda seria o comando para fazer *build e o terceiro um comando para fazer upload do binário construído na step anterior para um repositório de artefatos.
No código de exemplo do nosso primeiro pipeline temos:
name: Meu primeiro pipeline
on: [pull_request]
jobs:
ci:
runs-on: ubuntu-latest
steps:
- run: echo "🎉 Parabéns você criou seu primeiro pipeline"
Dentro do job chamado “ci” (que pode ser o nome que você quiser) temos apenas um step que é esse:
- run: echo "🎉 Parabéns você criou seu primeiro pipeline"
Esse step não faz nada de útil, é apenas didático para você entender como funciona um pipeline.
Dentro de steps no Github temos muitas coisas que podemos fazer e uma das mais usadas é run, que é a execução de um comando dentro da máquina que o Github Actions disponibilizou temporariamente para rodar o seu pipeline.
Todo comando que for informando no run ele execurará esse comando no terminal da máquina usada pelo seu pipeline. Normalmente você precisa configurar essa máquina para que ela possa fazer o que você deseja.
Vamos colocar outro step:
steps:
- run: echo "🎉 Parabéns você criou seu primeiro pipeline"
- run: apt-get update && apt-get install python
Na segunda linha ja fazemos algo de útil, mas é importante relembrar que tudo executado na máquina do pipeline. Nessa linha estamos atualizado a base do apt com apt-get updatee os símbolos juntos && no terminal Linux indicam que um outro comando será executado na mesma linha.
O segundo comando é apt-get install python que será responsável por instalar o Python nessa máquina, pois hipoteticamente esse código usará Python. E eu preciso das ferramentas para manipular meu código Python.
Existe uma outra forma mais fácil de configurar seu pipeline é usando um step diferente, que é uses
name: Meu primeiro pipeline
on: [pull_request]
jobs:
ci:
runs-on: ubuntu-latest
steps:
- run: echo "🎉 Parabéns você criou seu primeiro pipeline"
- uses: actions/checkout@v5
- uses: actions/setup-python@v6
with:
python-version: '3.13'
O uses é a opção que você pode usar uma especie de pacote do Github Actions que permite executando uma série de comandos e assim evitar que você fique fazendo eles manualmente.
Esse pacotes são chamados de actions e existe um action que quase sempre será utilizado que é o actions/checkout responsável por baixar o seu código para o mesmo lugar está executando todos os comandos no run. Sem o action checkout você não verá os arquivos ao executar qualquer comando.
Os actions que começam com actions/ são os actions oficiais do Github.
Os actions podem ser usados informando a versão deles. Isso é importante pra evitar comportamento inesperado quando a versão muda: actions/checkout@v5 o @v5 indica que usaremos a versão 5 desse action e se ele lançar qualquer versão 5.1, 5.1.2 ou qualquer versão que comece com 5, eu pegarei o código mais atualizado, mas quando ele lançar a versão 6.0.0 o pipeline usará sempre a ultima lançada na versão 5.
O segundo action apresentado no exemplo acima é setup-python ele é responsável por instalar os pacotes necessários para usar python.
steps:
…
- uses: actions/setup-python@v6
with:
python-version: '3.13'
Esse action permite que eu modifique o comportamento dele indicando um parâmetro predefinido, ou seja, quem criou esse action fez uma variável chamada python-version que ao colocar um valor ali dentro, eu indico qual versão do python quero instalar nessa máquina.
Separação por “job”
Como já sabemos que no pipeline existem várias steps, que são responsáveis por executar ações no código a medida que elas avançam na esteira de entrega de software, é importante salientar que existe um outro nível de abstração chamada de job. A tradução para português seria “trabalho”, mas usaremos o termo em inglês para facilitar seu uso no futuro, pois esse é o nome que muitas vezes é usado pelas ferramentas de mercado.
O job é um conjunto de steps, onde essas steps normalmente são executadas sequencialmente por padrão, ou seja, a segunda step só será executada após terminar a primeira.
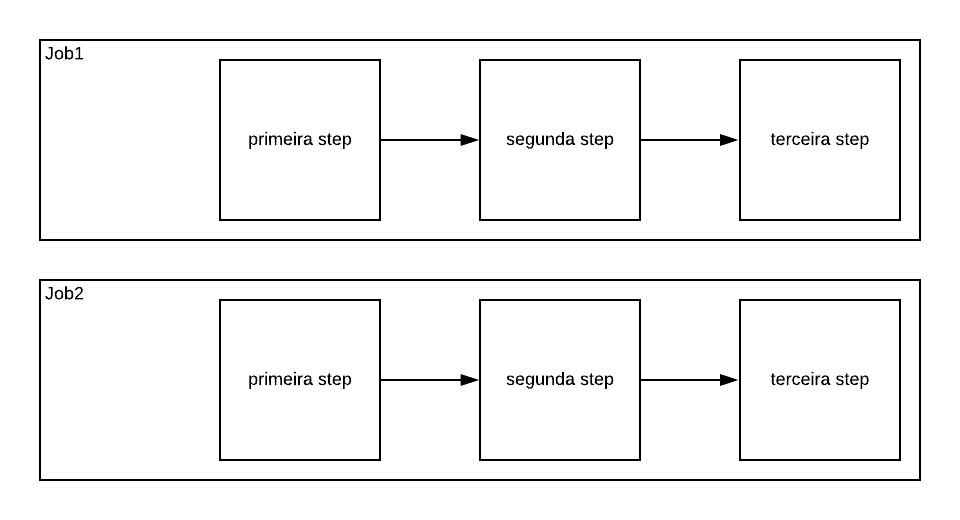
Se seu pipeline tiver vários jobs geralmente eles serão executados em paralelo, ou seja, se você tiver um job que executa seu código em uma plataforma específica, e um outro job que executa em outra. Os dois jobs serão iniciados ao mesmo tempo e não haverá nenhuma hierarquia entre eles, a não ser que seja explicitamente descrita.
Em nosso exemplo o pipeline tem apenas um job, e o nome dele é ci. Se você quiser pode criar outro job e colocar outras tarefas dentro dele.
name: Meu primeiro pipeline
on: [pull_request]
jobs:
ci:
runs-on: ubuntu-latest
steps:
- run: echo "🎉 Parabéns você criou seu primeiro pipeline"
- uses: actions/checkout@v5
- uses: actions/setup-python@v6
with:
python-version: '3.13'
Dentro de cada job é informado qual máquina executará essas tarefas descritas em steps. Em nosso caso o job ci será executado em um ubuntu-latest:
name: Meu primeiro pipeline
on: [pull_request]
jobs:
ci:
runs-on: ubuntu-latest
…
Quebrando o pipeline
Usualmente as ferramentas de pipeline só permitem que a segunda step seja executada se a primeira for finalizada com sucesso. Isso é um comportamento extremamente esperado, porque a ideia do pipeline é justamente garantir que as ações sejam executadas em sequência, pois elas em geral são configuradas de forma gradual, ou seja, as primeiras steps fazem as primeiras validações, e as construções e outras intervenções mais críticas e demoradas acontecem depois. Isso quer dizer que se uma validação inicial falhar, e essa validação por via de regra é mais rápida, poupa o tempo de esperar a falha da etapa de construção de artefato, que costumeiramente é mais demorada.
name: Meu primeiro pipeline
on: [pull_request]
jobs:
ci:
runs-on: ubuntu-latest
steps:
- run: echo "🎉 Parabéns você criou seu primeiro pipeline"
- uses: actions/checkout@v5
- uses: actions/setup-python@v6
with:
python-version: '3.13'
- run: python -m pytest
No exemplo acima, a última step é a execução dos testes automatizados usando o pytest. Se as etapas anteriores falharem, essa etapa de execução de teste não será executada, e isso é ótimo, pois se o código não passou por validações iniciais, ele provavelmente não está pronto para ser testado, e isso poupa o tempo de espera para que os testes sejam executados e falhem.
É comum encontrar pessoas afirmando que o objetivo de um pipeline é “quebrar”, pois é nesse processo que se percebe se o código enviado para esteira de fato está preparado para ser entregue ou não.
A automatização das validações e construções são parte central de um processo de entrega de software moderno.
Conclusão
O pipeline é uma abstração, onde temos jobs e steps compondo as etapas para construção de um produto a ser entregue no final da esteira. Tendo isso em mente, podemos pensar que muito mais do que apenas a ferramenta, o pipeline serve também para criar um fluxo rápido de feedback, onde em caso de quebra podemos entender que aquele código precisa de cuidados até que o problema seja resolvido.
Agradecimentos
- Obrigado a Somatório que revisou a primeira versão deste material antes dele sair e fez o mesmo com essa nova versão. Obrigado demais!
- Obrigado a Jonas Alberto que leu esse artigo e fez sugestões de melhoria, que foram incorporadas nessa nova versão.
- Obrigado a Daniel Moreto que leu o artigo e me deu ótimos feedbacks para melhora do texto.